之前在Windows平台上有一款文字识别软件叫做天若OCR,十分好用,然而我至今还没有找到在Mac平台上的类似软件(指免费的)。
那不如自己写一个!(需要python3环境,如果您没有安装过python3,也不用担心,macOS自带了python2.7,您只需要将文章中的pip3和python3命令更换为pip和python即可。)
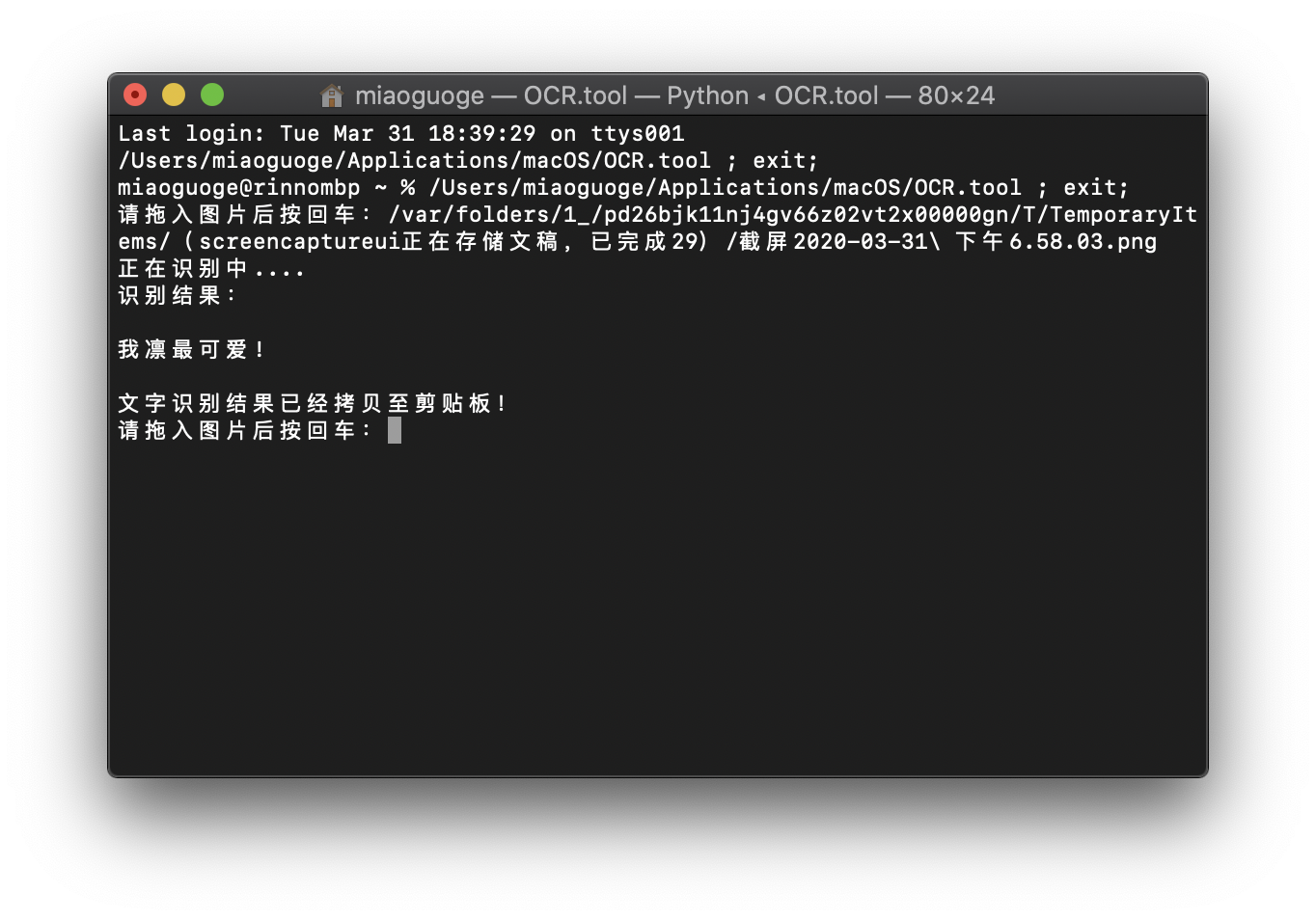
- 打开百度AI开放平台: https://ai.baidu.com ,点击右上角“控制台”,使用百度账号登录,点击左侧边栏的文字识别:
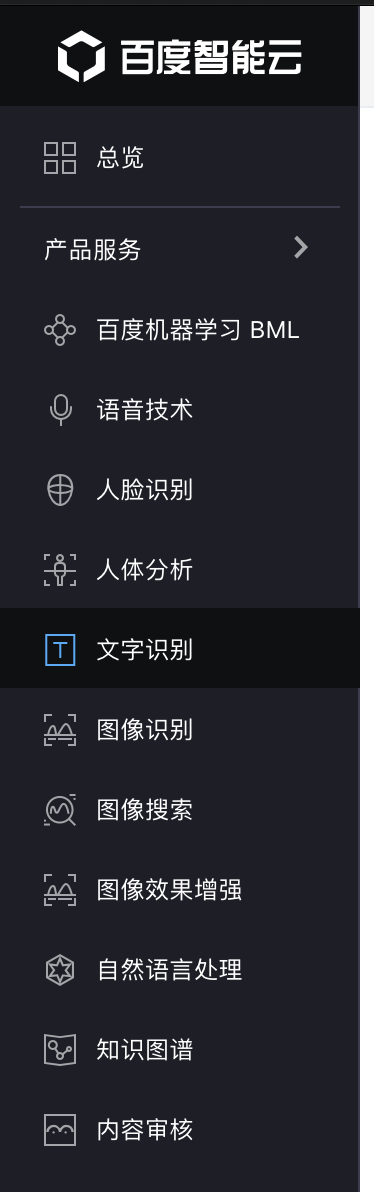
然后点击创建应用:
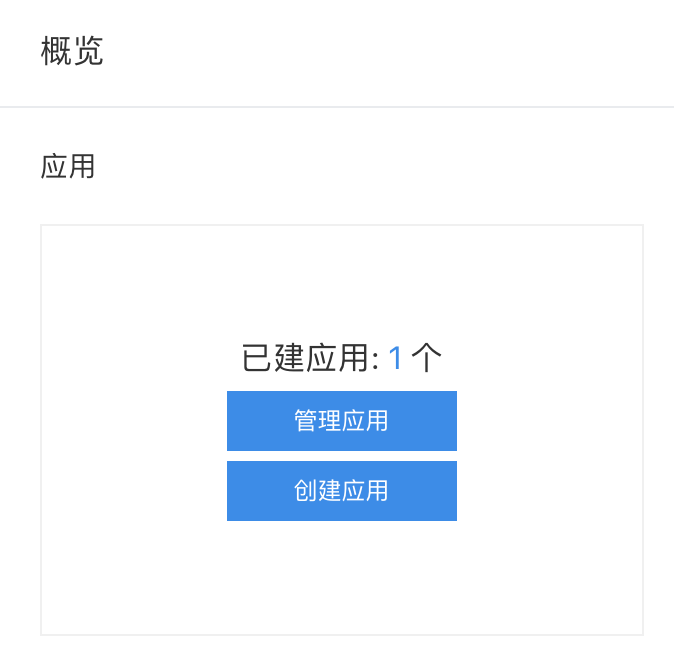
可以看到它为我们自动勾选了文字识别接口,填好其他信息之后点击创建,之后会来到“应用列表”,在这里可以查看AK(API Key)和SK(Secret Key)。
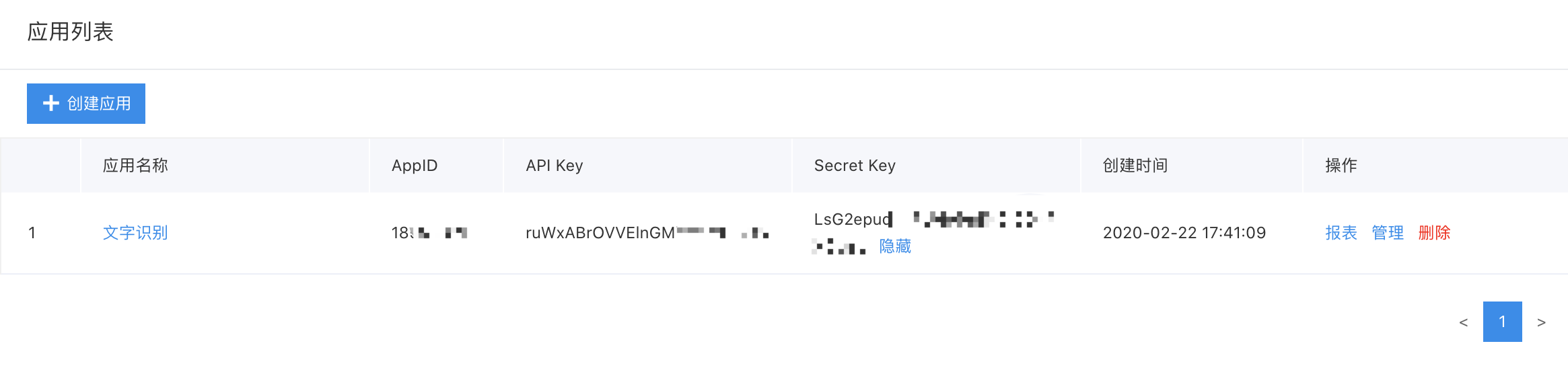
可以看到,百度提供的免费高精度文字识别是500次每天,足够我们用了。

- 打开终端,输入:
1
2
3
| pip3 install base64
pip3 install pyperclip
pip3 install requests
|
- 打开您的python编辑器,输入以下代码:
1
2
3
4
5
6
7
8
9
| import requests
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【您的AK】&client_secret=【您的SK】'
response = requests.get(host)
result = str( response.json() )
result = result.split('access_token\': \'')[1]
result = result.split('\'')[0]
print(result)
|
运行后显示出来的那一串字符,叫做access_token,将其复制保存好。
注意:由于百度的限制,access_token每隔一个月就会发生变化,所以每个月都需要重复步骤3,并将新的access_token嵌入以下的python代码中。
好一点的思路是在下面的py代码中先判断当前的access_token有没有过期,如果有,就自动调用以上代码生成一个新的,这样就不用每个月自己手动生成,也可以把两个文件合并成一个。
但是由于我的还没过期,还不知道access_token过期后百度返回的response是什么,也就无法在代码中判断。等一个月之后我会再来更新这篇文章的
- 新建一个python文件,输入以下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| import requests
import base64
import string
import pyperclip
request_url = 'https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic'
path = input("请拖入图片后按回车:")
path = path.rstrip()
path = path.replace('\\','')
print("正在识别中....")
f = open(path,'rb')
img = base64.b64encode( f.read() )
f.close()
params = {"image":img}
access_token = '【填写您的access_token】'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
result = str( response.json() )
result = result.split('[{\'words\': \'')[1]
ans = result.split('\'}, {\'words\': \'')
out = ""
for i in ans:
out += i
out = out.split('\'}]}')[0]
print("识别结果:\n")
print(out)
pyperclip.copy(out)
print("\n文字识别结果已经拷贝至剪贴板!")
|
- 保存后,在您喜欢的地方新建一个文本文件,输入:
1
2
3
4
| while true
do
python3 /Users/hoshizora/Developer/Python/baidu-OCR.py #这里改成您的py文件所在的绝对路径
done
|
保存后有两种选择:
将其重命名为OCR.tool (名称随意,后缀名为.tool)。
把txt后缀名删掉,只留下OCR这个文件名,然后打开终端,进入当前文件夹,输入
回车后您会发现原来文本的图标已经变成了可执行文件的图标:

之后在使用时,按下Command+Space调出聚焦,输入“ocr”回车,即可打开文章开头的那个界面。将图片拖入后,回车即可识别。
如果是现场截图识别的话,按下Command+Shift+4,,在Touch Bar上选择存储到桌面:

截图后直接将右下角出现的预览图片拖入终端窗口中回车即可识别。(不会在桌面上留下截图文件)
2020年4月29日更新
今天用的时候发现过期了,就更新了代码。
首先在您的python文件同目录下新建一个名为access_token.txt都文本文档,在里面放入您当前的access_token,然后将以下代码复制到您的python文件中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| import requests
import base64
import string
import pyperclip
request_url = 'https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic'
path = input("请拖入图片后按回车:")
path = path.rstrip()
path = path.replace('\\','')
print("正在识别中....")
f = open(path,'rb')
img = base64.b64encode( f.read() )
f.close()
params = {"image":img}
f = open('access_token.txt')
access_token = f.readline()
f.close
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
result = str( response.json() )
isExpired = result.find("Access token expired")
if (isExpired>0):
print("鉴权码已过期,正在为您自动获取中")
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=ruWxABrOVVElnGMbwnmO8qfV&client_secret=LsG2epudjr4RUHp1grIM0r6G47X9cglL'
preResponse = requests.get(host)
access_token = str( preResponse.json() )
access_token = access_token.split('access_token\': \'')[1]
access_token = access_token.split('\'')[0]
f = open('access_token.txt','w')
f.write(access_token)
f.close
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
result = str( response.json() )
result = result.split('[{\'words\': \'')[1]
ans = result.split('\'}, {\'words\': \'')
out = ""
for i in ans:
out += i
out = out.split('\'}]}')[0]
print("识别结果:\n")
print(out)
pyperclip.copy(out)
print("\n文字识别结果已经拷贝至剪贴板!\n")
|
然后用文本编辑打开OCR.tool:修改其为:
1
2
3
4
5
6
| cd
while true
do
python3 baidu-OCR.py
done
|
